在机器学习以及神经网络领域,人们经常借助Numpy库中的随机函数来生成随机数,例如,用于随机设定神经网络参数权重W。需要注意的是,W的初始化不能全为零,否则会导致对称破缺问题,进而使得隐藏层中配置多个神经元变得毫无意义。
在Numpy库中,我们经常运用np.random.rand()、np.random.randn()以及np.random.randint()这三个随机生成函数。这些函数各自有着不同的特点:,
(1)np.random.randn()函数
语法:
np.random.randn(d0,d1,d2……dn)
1)当函数括号内没有参数时,则返回一个浮点数;
若函数内部仅含有一个参数,则输出的结果将是一个秩为1的数组,这样的数组无法用来表示向量或矩阵。
若函数的括号内包含两个或更多参数,它将输出一个对应维度的数组,该数组可以用来表示向量或矩阵。
函数与np.random.randn()功能相近,不过np.random.standard_normal()的调用时需要传入一个元组作为参数。
在使用np.random.randn()函数时,其输入参数通常是整数形式,然而,若输入为浮点数kaiyun全站网页版登录,系统会自动将其直接截断,转换成整数类型。
作用:
通过本函数可以返回一个或一组服从标准正态分布的随机样本值。
特点:
这种正态分布以0作为其均值,1作为其标准差,通常表示为N(0,1)。其对应的正态分布曲线图如下所示kaiyun.ccm,即:
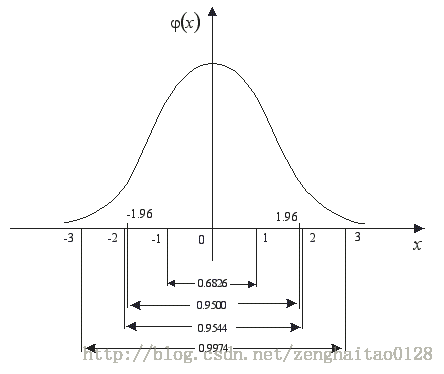
标准正态分布曲线下面积分布规律是:
在-1.96至+1.96的区间内,曲线下方所覆盖的面积达到了0.9500,这表示在此区间内取值的概率为95%。同样地,当取值范围扩大至-2.58至+2.58时,曲线下方的面积增至0.9900,对应的概率则为99%。
因此,使用np.random.randn()函数生成的随机样本,其数值大多集中在-1.96至+1.96这一区间,尽管也有可能产生较大的数值,但这种情况发生的概率相对较低。
用例:

应用场景:
在神经网络构建过程中,权重参数W一般通过特定函数进行设定。然而,有一点必须留意,我们通常会在生成的矩阵上乘以一个较小的数值,例如0.01,这一操作的目的是为了加速梯度下降算法的收敛过程。
W = np.random.randn(2,2)*0.01
(2) np.random.rand()函数
语法:
np.random.rand(d0,d1,d2……dn)
注:使用方法与np.random.randn()函数相同
作用:
本函数能够生成一个或多个在“0至1”区间内均匀分布的随机数值样本。这些样本的数值区间为,。
0,1),不包括1。
在深度学习的Dropout正则化技术里,我们能够用来构造dropout随机向量(简称dl),比如通过设定保留神经元的比例(以keep_prob表示):该向量dl的计算公式为np.random.rand(al.shape,al.shape)。< keep_prob
用例:
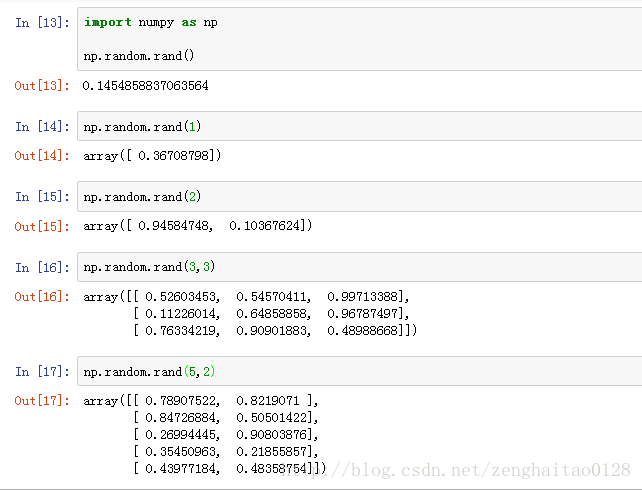
(3) np.random.randint()函数
语法:
输入:
low—–为最小值
high—-为最大值
size—–为数组维度大小
dtype—为数据类型,默认的数据类型是np.int。
返回值:
返回随机整数或整型数组,范围区间为
low,high),包含low,不包含high;
high没有填写时云开·全站体育app登录,默认生成随机数的范围是
0,low)
用例:







