欢迎遵循研究生入口考试系列!本文将在研究生入学考试系列中开设第一篇文章。
这个周末是年度研究生入学考试季节中最重要的两天。为了帮助大三学生在心理学专业课程的统计部分更好地冲刺,我们根据以前的注释和经典参考材料在此心理统计考试之前编制了关键知识冲刺。我们衷心希望每个人都能在2024年实现自己的梦想,并进入他们梦dream以求的学校!
也欢迎每个人跟随并转发它,以帮助您周围有需要的更多朋友。将来,我们将继续发布与研究生入学考试有关的更多内容。
部分关键知识汇编
第1章集中量数(算术平均,中和模式)
1。算术平均值需要知道如何计算种群,样本和加权平均值。平均值极大地受到极值的影响,但最少受到抽样变化的影响。
2。中等数字的计算很容易犯错。数据的数量均匀且奇怪,是否有重复的中等数字,有必要区分计算方法。使用的数字是:极端值;个别数据尚不清楚;代表价值的快速估计;顺序尺度。
3。模式是最多的数字。
4。正向偏斜分布(右侧的尾巴):平均值>中间>模态;
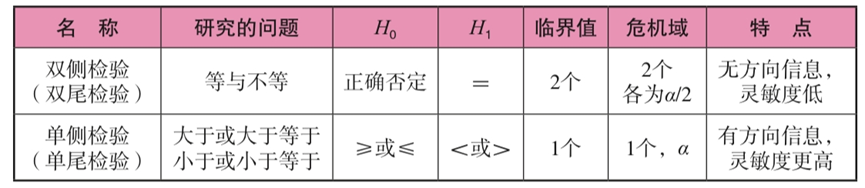
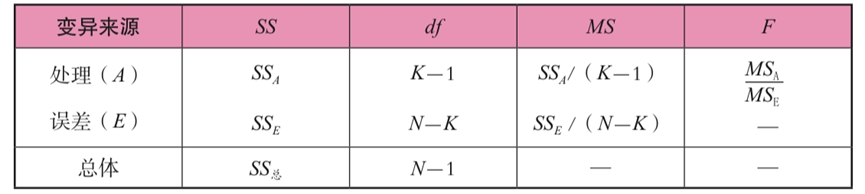
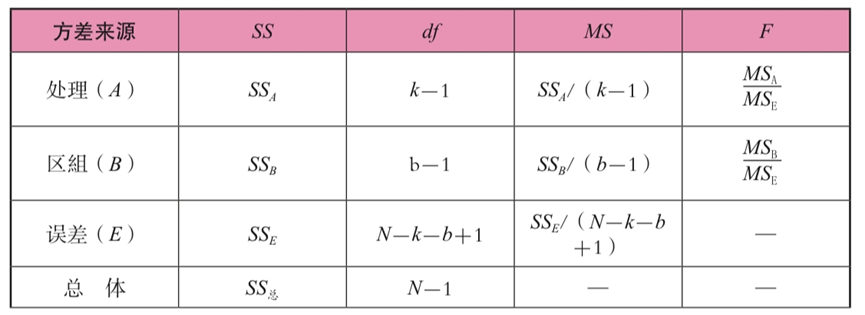
负偏斜分布(左侧):平均值<中 正态分布:平均值=中=模式。 第2章差异 1。分离和差异之间的差异和负面之间存在差异,而分离之和始终为0。 2。寻找样本方差和样本标准偏差的目的是推断人口差异和人口标准偏差。 3。方差和标准偏差的属性:所有观测值均使用恒定C添加,并且方差和标准偏差保持不变;如果将所有观测值乘以常数C,则方差将扩大C的平方时间,并且标准偏差会扩大C时间。如果将所有观测值乘以常数C,并且添加常数D,则方差会扩大C的平方时间,并且标准偏差会扩大C时间。 4。差异和标准偏差的评估: 优点:严格的计算,对响应敏感,加性性能是分析变异原因的绝佳指标,并且具有广泛的应用;缺点:它容易受到极端数据的影响。 5。比较变异系数的分散程度(方差系数):该系数没有单位,计算公式为 第3章相对数量 1。如果百分比对应于70点40,则意味着40%的病例小于70点。 2。标准分数μ= 0的平均值,标准偏差 。 3.将原始分数转换为标准分数无法改变原始分数的属性和分布,并且非正常的分布数据不能归一化。标准分数不等于标准正态分布。 z得分是一个等距变量。 第4章相关计数 1。两个具有相关性的变量不一定具有因果关系。 2。当线性相关系数为0时,两个变量之间存在无线相关性,但是可能仍然存在曲线相关性。 3。产物差异相关:产品差异相关的计算条件是两个数据都是连续变量。找到30多对数据对之间的相关性。这两个变量都符合正态分布并具有线性相关性。 4。Spearman级别的相关性:仅在两个变量都是层次变量时才使用。它的准确性不像产品差异那么重要。 5。肯德尔和谐系数:当您想同时研究三个或更多变量的一致性或相关性时,您可以使用Kendall Harmony系数。 6。质量相关:点二列相关性用于两个变量kaiyun.ccm,一个是连续变量,另一个是一个客观的二分法变量(例如男性和女性);两个列相关用于两个变量,一个是连续变量,另一个是原始的连续变量,但人为地分为二分法变量(例如,考试分数除以60个标准要通过)。 7。相关:相关系数的平方是确定系数,表明因变量y的变化有多少百分比可以通过控制自变量x来解释。 第5章概率分布 1。随机抽样应符合以下两个条件:首先,人口中的每个人都有相同的选择机会;其次,如果要在样本中选择多个个体,则每个选择的概率应该是恒定的。 2。正态分布:加上或减1标准偏差(68.26%);加上或减去2个标准偏差(95.44%);加上或减去3个标准偏差(99.74%)。这是与标准正态分布的“一般和个人关系”。平均值越大,曲线移动越多。 3。二项式分布:当NP大于5和N大于30时,大约正态分布。 4。t分布:钟形,单峰对称性,平均0。与正态分布相比,t分布在中间较低和陡峭,两侧较高且温和。 DF越大,t分布越接近正态分布。 5。F分布:F分布的最大特征是其形态受到两个自由度的限制。一个是分子自由度df1 = n1-1,另一个是分母自由度df2 = n2-1。 第6章概率抽样 1。简单的随机抽样(绘图方法,随机数字表方法),机会平等和相互独立的原理。 2。层次抽样适用于种群较大并且样本较小且整体结构复杂的情况。 3。等距采样也称为常规采样。如果人口周期性变化,则该方法将不适用。 4。分阶段采样,采用两次或更多次的简单随机抽样方法,最后获取样品。 5。三种不同分布的特征:人口分布是固定的;样品分布随着每个样本的绘制而变化,每次都不同。抽样分布只有一个人群的统计数据。 第7章参数估计 1。判断估计质量的标准:无偏见,有效性,一致性和充分性。 2。标准偏差和标准误差:标准误差是“采样分布的标准偏差”。 3。间隔估计和置信系数 4。影响置信区间长度的因素:置信系数 样品容量n越大,样本方差越小, 置信区间越长。 5。人口平均值的估计和计算步骤:计算样本平均值和标准偏差 - >计算标准误差(б) - >确定置信度和显着性水平 - >基于采样分布的后续表(z或t) - >计算置信 间隔 - >文本说明(间隔[] 概率涵盖了原始种群参数μ)。 6。在4种不同情况下的人口平均值的估计 第8章假设检验 1。心理统计中的普遍显着性水平(α)为0.10、0.05、0.01。 α越小,显着性水平越高,也意味着事件误差的概率越小。 2。通常,在假设检验中,它是基于两种假设的测试。也就是说,虚无和替代假设的假设。虚无的假设是一个零假设(零假设),以H0为代表。虚无的假设通常假定总体参数没有改变,也不是实际差异。替代假设通常是徒劳假设的相反假设,即假设已改变的假设(通常是研究人员需要确认的假设),称为H1。这两个假设总是成对出现,并且是相互排斥的。通常,首先建立替代假设,然后建立虚无的假设。 3。在统计决策中,可能会犯两种错误。当H0为真时。但是,如果错误拒绝了H0,则将产生一个类误差(α)。当H0错误但接受错误时,会发生II类误差(β)。请参阅《亮点图》部分)。 4。建立测试的方向性和假设(请参阅关键图表部分): 一个。单向(1个临界值,一个危机域:α): I.LEFT:H0:U1≥U0,H1:U10 ii。右:H0:U1≤U0,H1:U1> U0 b。双向(2个临界值,两个危机域:2/α):H0:U1 = U0,H1:U0≠U1 5。α和β是一个人的崛起与对方的崛起之间的关系。 α和β大小的变化决定了统计能力的大小(1-β)。如果α变大,β变小,1-β变大,目前统计功率大小增加。影响统计疗效的因素包括治疗效果的大小(较大,更强的→阳性关系),测试的方向性(单侧>双侧),样本量的大小(较大,更强→阳性关系)以及真实值与伪值的差异(较大,较大,较大,强→正相关关系)。 一个。效果数量D:d = 0.2应视为低效果,d = 0.5应视为中等效应,d = 0.8应视为高效应。 6。单人群平均显着性测试。 一个。总正态分布,方差已知,然后x的采样分布遵循n(μ,σ2/n)的正态分布,并使用z检验。 b。种群是正态分布,方差尚不清楚,然后x的采样分布遵循t分布,df = n-1,使用t检验。计算t值时人口的种群差异可以用样本方差S2替换。 ,S = S N-1 c。总体分布是非正常的分布,但n≥30,t分布大约是z分布,并且使用z检验。统计或表示为Z'。 ,S = S N-1 7。双重人口平均值之间的差异测试。 一个。两个人群都是独立的,并且差异是已知的。带有两个样本平均值之间差异的样品采样分布遵循正态分布,使用Z检验。 b。这两个种群是独立的,差异是未知的,但是已知两个人群的方差相等。样品采样分布与两个样本平均值之间的差异遵循t分布开yun体育app官网网页登录入口,df = n1 + n2-2。使用t检验。 c。这两个人群是独立的,方差是未知且不相等的,但样本量很大。两个样品平均值之间差异的样品采样分布大约是正态分布。统计量是z'。 d。众所周知,这两个样本具有n对数据。如果两个群体相关,并且相关系数r是已知的。采样分布遵守t分布t分布S2D = S21 + S22-2RS1S2的方差 ,df = n-1。使用相关系数计算得出的t值相对较大。尽管这将导致I类错误增加,但它将增加统计功率。 8。差异均匀性测试。先决条件:两个人群彼此独立。假设H0:σ21=σ22,H1:σ21≠σ22。方差测试的同质性是两侧测试。采样分布F = S21/S22,遵守DF1 = N1-1的F分布kaiyun全站网页版登录,DF2 = N2-1。 9.最后,让我们总结假设检验的步骤: 1)提出假设H0或H1; 2)根据上述摘要选择适当的统计信息; 3)指定显着性水平(α变大→拒绝域变大→发生I类误差的概率); 4)计算; 5)对此做出决定。 第9章方差分析 方差分析: 1)可以同时检测到两个以上的平均值的差异; 2)它可以解释几个因子水平之间的相互作用; 3)可以分析来自总变体中不同来源的变化。 1。方差分解(方差是独立的): 一个。总体分散总和(总计): b。组内的正方形总和(SS;正方形误差总和): c。两组之间的正方形总和(SSS;过程离散的正方形总和): d.ss total = s内部 + ss房间 e。均值之间的差异的重要性是从样本方差比:Interms/ms得出的 2。方差分解是方差分析的基础。需要满足以下条件才能分解差异: 1)总体分布; 2)第二,样品是随机的; 3)总体差异同质性(由Hartley的差异均匀性测试/Hartlet的最大F值测试实施) 3。差异的完全随机设计分析(一个因子A,受试者之间有不同的治疗方法→设计), 一个。每种处理的平均平均值x̄1,x̄2,x̄3,...,x̄n和人口平均值x̄。 b。建立假设:H0:μ1=μ2=…=μK,H1:至少两μs不相等。 c。计算: 我。计算总分散体的正方形总和(SS总): ii。计算组内的正方形总和(误差正方形之和; SSE): 1.MSE = SSE/(NK) iii。计算两组之间的平方之和(平方之和的处理; SSA): 1.MSA = SSA/(K-1) d。制作ANOVA表:请参阅关键图表部分 e。测试结论:确定F值(MSA/MSE)是否大于临界值。 4。随机块设计的方法:(每个主题都经历了所有处理→主题内的设计) 一个。重新定位组内的差异(组之间的总分散总和(SSB) +随机误差的总和)→系统误差的分离,提高随机误差的纯度,减少MSE,从而提高测试的灵敏度。 b。有不同的平均值x̄.j(x̄.1,x̄.2,x̄.3,...,x̄.n),以及每个接受治疗的平均值(相互障碍)的平均值(相互障碍)的平均值。 (x̄1。,x̄2。,x̄3。,...,x̄n。)。 c。建议的假设:(两个) 我。关于处理间隔:H0:μ1=μ2=…=μK,H1:至少2μs不相等。 ii。关于以下内容:H0:每个块H1之间没有区别:至少两个块之间存在差异。 d。计算: I.SS总数: II.SS A: 1.MSA = SSA/(K-1) 2。 III.SS B: 1.MSB = SSB/(B-1) iv.sse: 1.MSE = SSE/(NK-B+1) e。制作ANOVA表:请参阅关键图表部分 f。决策: 我。如果该过程的F值MSA/MSE超过临界值,则意味着处理结果很重要 ii。如果块效应的F值MSB/MSE超过临界值,则意味着块效应结果是显着的 5。最后,如果结果表明治疗之间的差异并不显着,则整个测试将完成。如果差异很大,则需要测试后。条件之间的多个相互比较将增加I错误,因此,为了比较第一种类型的错误,通常使用的是NK测试方法(也称为Q测试方法),最小显着差异方法(LSD)和Duncan多范围测试方法。 第10章线性回归 1。回归分析和相关分析之间的差异:回归分析是关于变量之间的关系,相关分析与这种关系的亲密程度有关。回归的结果并不代表因果关系。 2。线性回归的基本假设: 一个。线性关系假设 b。正态性假设 c。独立性假设(对应于Y的独立性和误差的独立性) d。分散类型的假设,例如错误 3。线性回归公式:y =α+βx。 β是通过x的线性回归获得的回归系数,而α是截距。它们来自最小二乘法。 4。线性回归测试: 一个。方差方法分析:回归系数的有效性取决于F(MSR/MSE)的显着性。 5。确定系数R2是回归差的正方形和差差的总正方形之和的比例,并且是回归方程有效性的指标。 一个。如果y至x的回归系数为b,并且x至y的回归系数为b',则b·b'= r2 = r2。请注意,b·b'≠1。 6。如何增加回归方程R2的拟合 1)考虑X合适的变量; 2)降低X变量之间的多重共线性; 3)X变量不包括Y的非线性关系; 4)增加样本量。 第11章卡方测试 1。3卡方检验的基本假设: 1)分类是相互排斥的和包容的; 2)观察结果彼此独立; 3)预期的次数需要为> = 5 2。卡方检验的基本公式: 健身测试,df = k-1, 独立测试,DF =(R-1)×(C-1) 3。持续校正较小的预期时间: 1)增加样品的数量; 2)删除样品数量; 3)细胞合并方法; 4)使用更正公式 4。卡方的性质: 1)这是实际数据和理论数据之间差异程度的指标; 2)主要用于次数; 3)计算值仅遵守χ2分布,并受到自由度的影响; 4)χ2总是积极的; 5)添加剂 5。四网格表(2х2偶性表)公式(不要忘记分母的正方形符号) 6。列联系电话: 第12章对多个统计的初步分析 1。多元回归分析,X变量应小且精制。 2。主成分分析:保持变量不变的总差异,以使第一个变量具有最大差异,并且称为第一个主组件;使第二个变量的差异与第一个变量相关,而被称为第二个主组件...等等,k变量具有k主组件。保留的主要组件越少,越好。通常,使用特征值规则,即保留其特征值大于或等于1的主要成分。 3。因子分析是为了探索观察变量背后的潜在结构,包括探索性因素分析和验证性因素分析。 第13章非参数测试 1。非参数测试的特征: 优点包括:1)不需要严格的假设(最大优势); 2)非常适合顺序变量; 3)非常适合小样本案例; 4)简洁而快速的计算,并具有良好的鲁棒性; 缺点包括:1)未能充分利用数据的所有信息,因此精度降低了; 2)无法处理互动。 2。独立样本平均值差异的非参数测试方法包括(级别等级):秩和测试方法,中号测试方法和革兰氏一条路ANOVA(对应于方差分析的完整随机设计)。 3。相关样本平均值差异的非参数测试方法包括(符号费用):符号压力降低阀,符号等级测试方法和两因素等方差分析(随机块设计对应于方差分析)。 B部分密钥公式部分 (注意:您可以先回忆起它,然后参考图片中的答案进行测试) 1。变异系数的计算 2。总体平均测试(单一/双重人群,已知方差/未知等) 3。皮尔逊产物差异相关(两列;配对,正常,连续,线性) 4。Spearman等级相关(两列;成对名称或顺序) 5。肯德尔等级相关性(多重,评估者的可靠性,[0,1]) 6。与质量有关 一个。点第二列相关(正确的两个点) b。两列相关(人为两点) 7。质量相关 8。线性回归 C部分密钥图部分 答:统计决策中可能犯的两种错误 B.假设检验中的双面测试和单方面测试的比较 C.分析方差形式 一般方差分析表 随机方差分析表 参考: 作者的笔记和“为心理学的关键和困难研究研究手册(第八版)的基本准备工作” 我希望我们的文章能为您提供有用的信息,也希望您可以更多地关注并转发它们以使更多的学生受益。将来,我们将继续为您提供更多高质量的研究生入学考试与内容相关的内容,以帮助您实现梦想。 明天,提高自信的帆,面对梦的阳光,然后航行到成功的另一侧。我希望所有候选人都一场顺利的考试,一件金牌的问题涌入天空,他们的梦想成真!快点!