目录
位图数据结构
超隙数据结构
Redis中的超置槽
Hyperloglog的核心思想
REDIS群集一致性哈希算法
使用哈希获取模具的问题
一致的哈希算法
一致哈希算法的容错和可伸缩性
哈希环的数据偏斜问题
位图数据结构
操作的最小单位是位
位图,一系列位。基础数据类型实际上是一个字符串,字符串本质上是一个大二进制对象,因此可以将其视为位图。
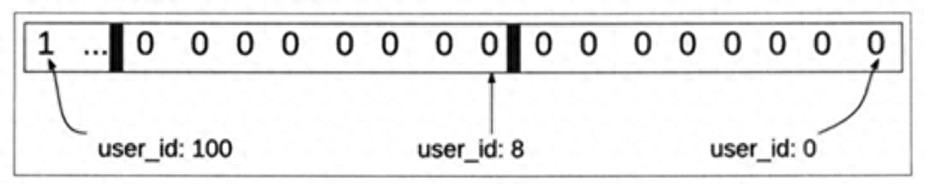
在实际生产中,位图可以用作标志位,0和1
超隙数据结构
Hyperloglog通常用于计算集合中非重复元素的数量。当一个新元素包含在集合中时,如果不包括在内,它将被添加;如果将其包含在集合中,则不会添加,计数值是元素的数量,但是有两个问题:
使用组合类型时,HyperLogLog可用于优化内存和性能问题。
HyperLogLog本身不存储数据。
HyperLoglog使用固定数量的内存(12KB)。
Hyperloglog可以最大程度地计算2∧64个不同元素的基数。
基础超置槽使用Bernoulli分布算法,因此返回的基数不准确开yun体育app官网网页登录入口,误差为0.81%。
Redis中的超置槽
Redi使用16384(2∧14)的存储桶来实现HLL结构,使标准误差达到0.81%。
REDIS使用的功能具有64位输出,前14位用于解决“桶”,其余50位用于计算左侧的0数(连续数为0)。每个存储子集将存储最大的“连续0号”,最大可能的50个(64位地址,其余50位存储“连续0号”)。每个存储子集需要使用6位(2∧6位)存储“连续0号”。 16384桶为98304BIT云开·全站体育app登录,将其转换为字节,即98304/8 = 12288字节= 12KB,因此在Redis中,每个超置logog均占12KB。
Hyperloglog的核心思想
除元素的14外,最左边的“连续0号”来推断元素的数量,例如:
要将其扔到当前,我记录的最大左侧计数为3是3,所以我有一些依据推测您投掷了23个元素。但是,为了使计算更加准确,超置槽种采用了铲斗机制。我将使用许多存储桶来记录单独出现在存储桶中的最大连续零数字。然后,使用每个存储桶的最大连续0数来倒转基数,最后使每个桶的倒置基数使每个桶的反向基数结果的平均值作为最终推断的基数;
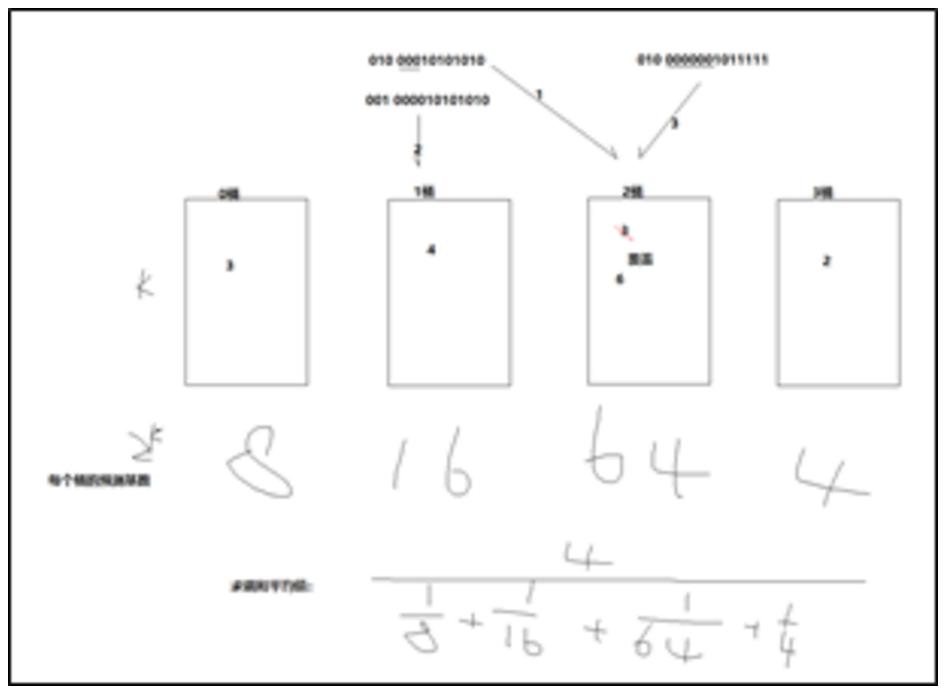
首先使用连续0的数量来推断元素的数量,然后调和和平均所有存储桶中的元素数量,以减少极端值对结果的影响
严格的数学证明需要数学知识,例如Bernoulli分布,多个Bernoulli实验和可能性估计。请参考:
一篇文章可以理解一个很有可能的估计值
REDIS群集一致性哈希算法
在REDIS群集中,使用Hash Modulo(Master Number)将数据的分布位置定位。
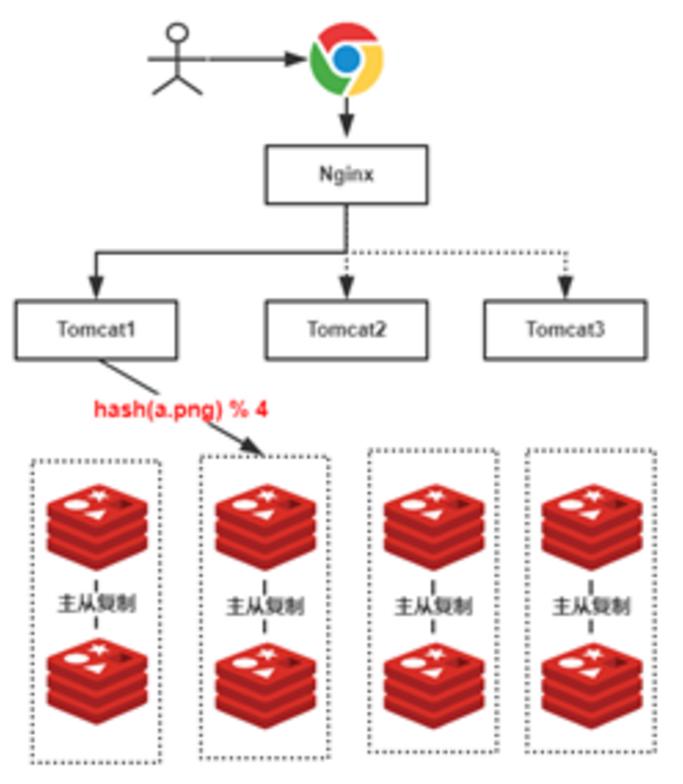
使用哈希获取模具的问题
尽管使用hashcode调节主可以快速定位机器位置,但是当群集增加或机器下降时,主模拟物对MODULO的值将变化,从而导致缓存位置的变化。 REDIS缓存雪崩,当应用程序无法从缓存中读取数据时,将从数据库中读取数据。
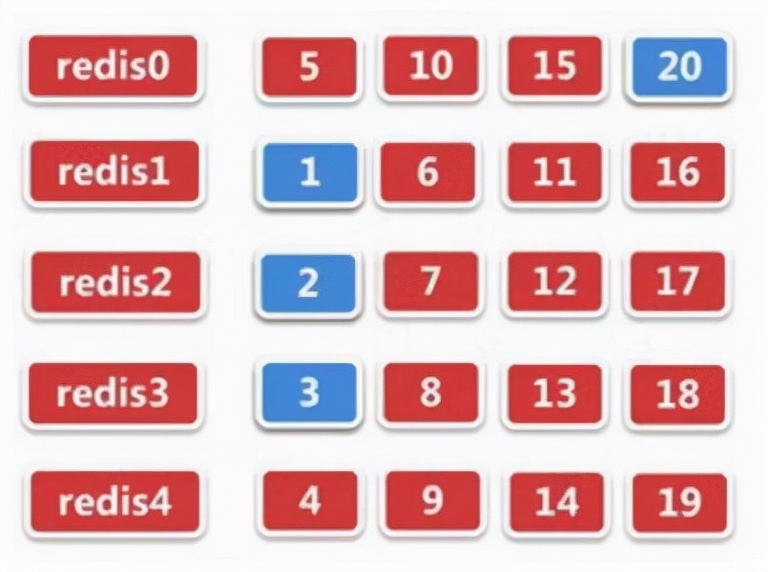
假设:我们添加了一个缓存服务器,并且缓存服务器的数量将从4变为5。然后,哈希(A.PNG)%4 = 2的原始公式变为哈希(A.PNG)%5 =? 。假设需要存储20个数据,而当有4个redis节点时,下图如下:

添加1个redis节点后,数据分布如下图所示:
一致的哈希算法
一致的哈希算法无法完全解决机器增加或减少引起的高速缓存故障问题,但只能减少对Redis Cache的影响。
一致的哈希算法也使用模量方法,但在它是服务器数量的模量之前,而一致的哈希算法使用2∧32-1的模量。一致的哈希算法将整个哈希值视为一个圆,例如假设哈希函数的值h为0〜(2∧32-1)
整个哈希戒指如下:
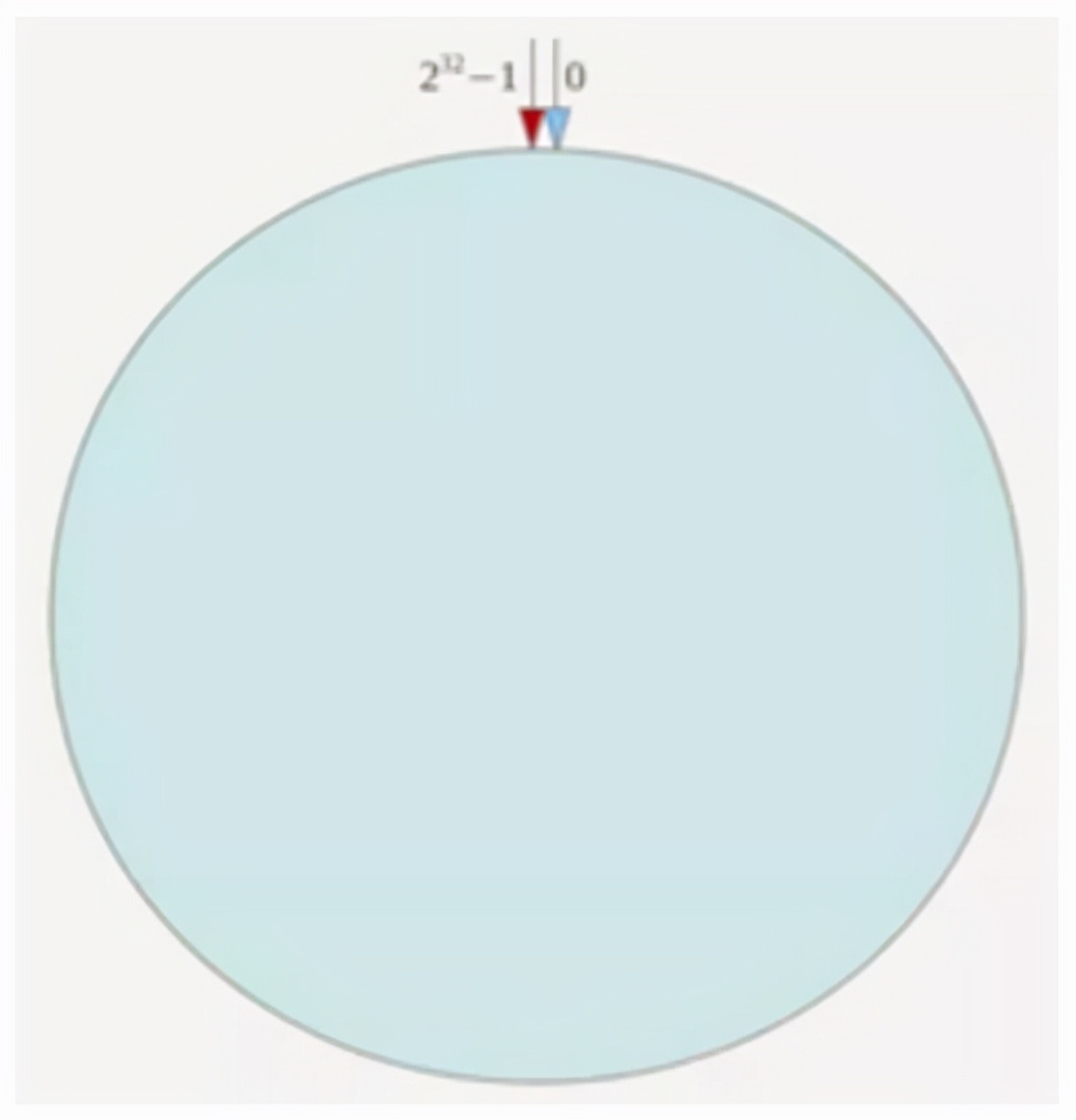
整个空间是顺时针组织的,环上方的点代表点0,0的右侧的第一个点为1,依此类推,直到2∧32-1和2∧32-1在零点重叠,我们称此环为hash环。
然后,您可以选择每个服务器的IP或主机名作为哈希的关键字,以确定Hash Ring上每台机器的位置,如下所示:
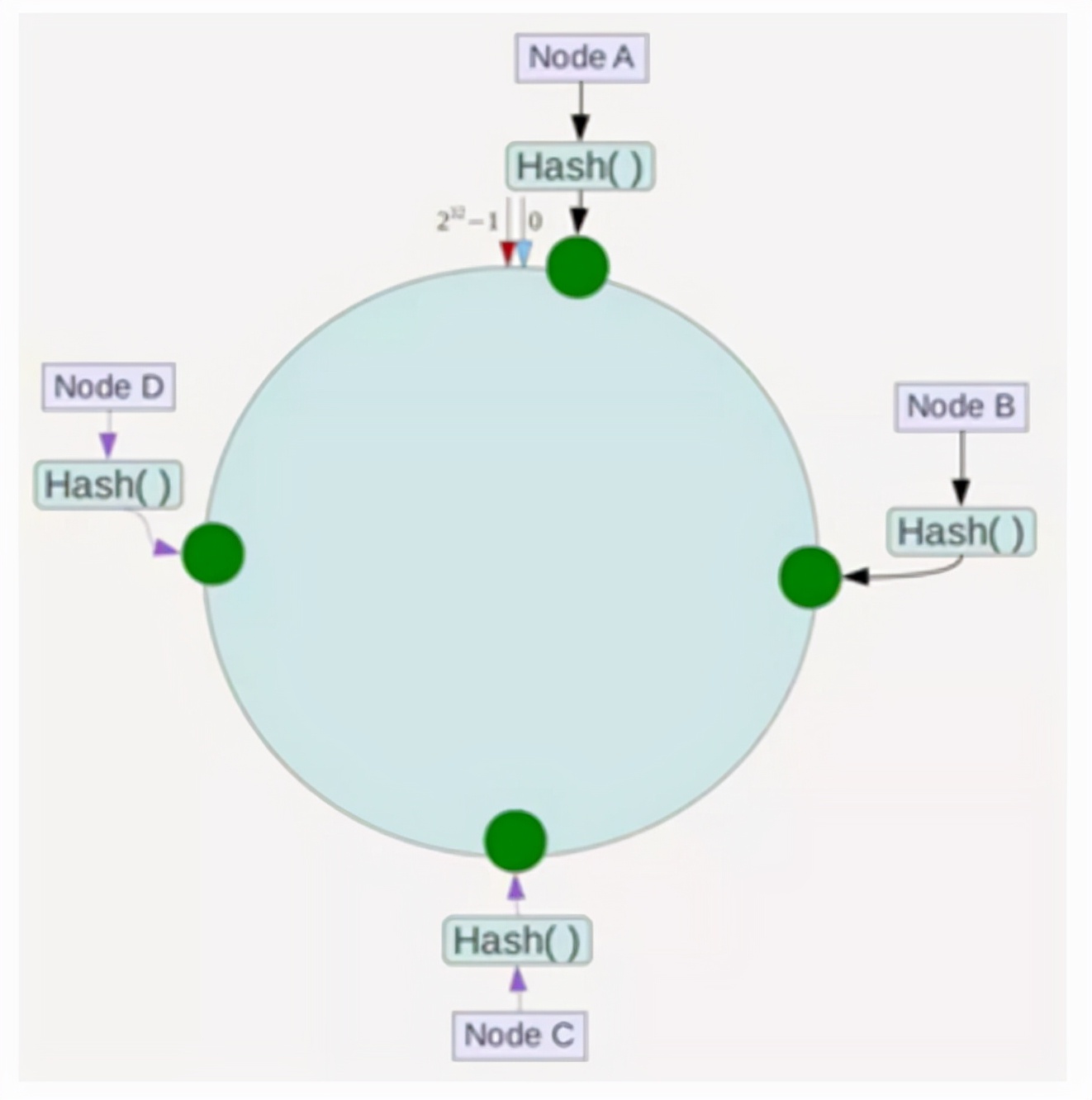
接下来,使用以下算法定位数据以访问相应的服务器:使用相同的函数哈希计算哈希值,并确定此数据在环上的位置,并从该位置从环上顺时针方向“行”。您遇到的第一个服务器是应该找到的服务器!
例如,我们有四个数据对象:对象A,对象B,对象C和对象D。在哈希计算后,环空间上的位置如下:
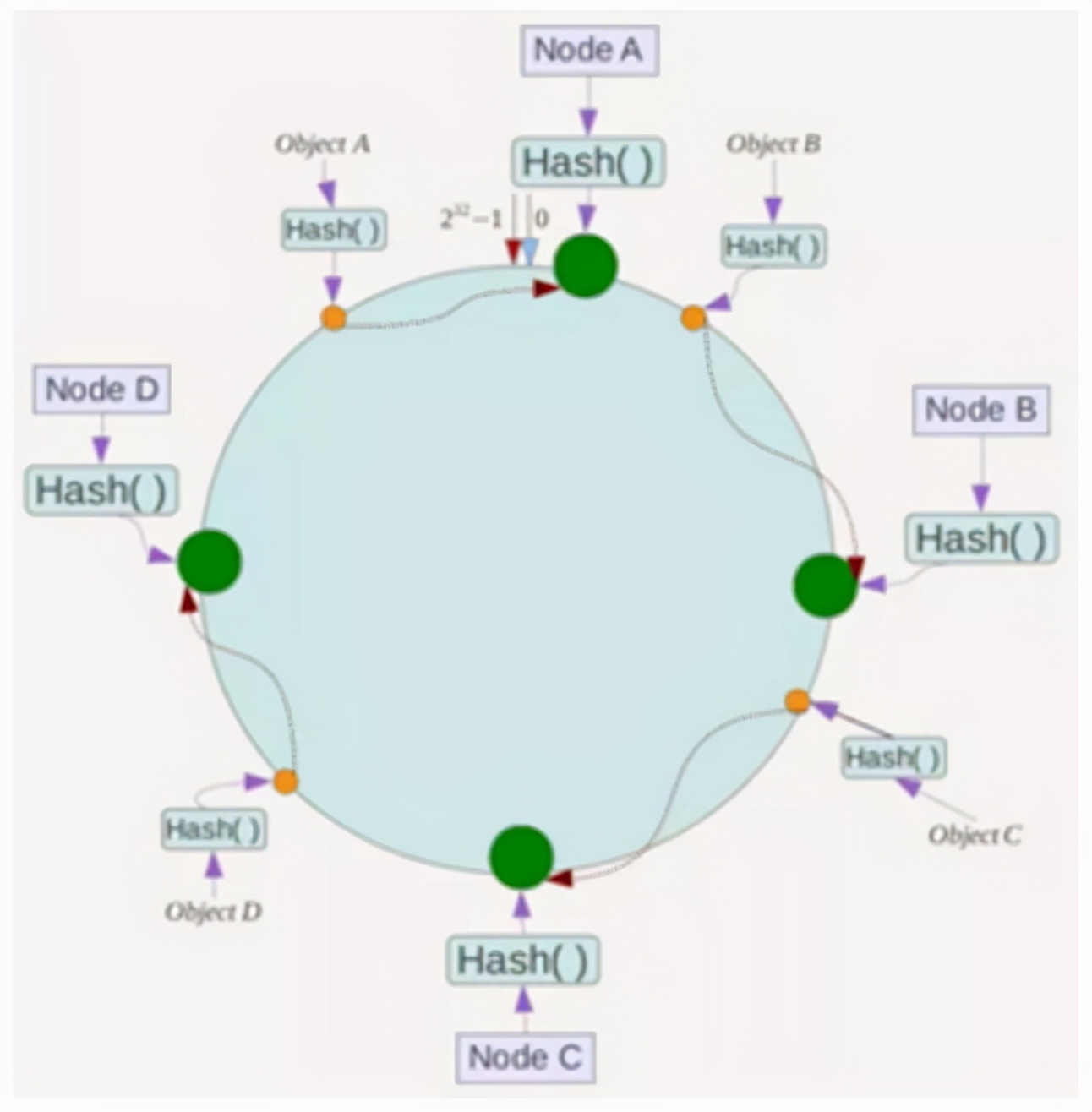
根据一致性哈希算法,将指定为节点A的数据A将指定为NODE B,C将指定为NODE C,并且D将指定为NodeD。
一致哈希算法的容错和可伸缩性
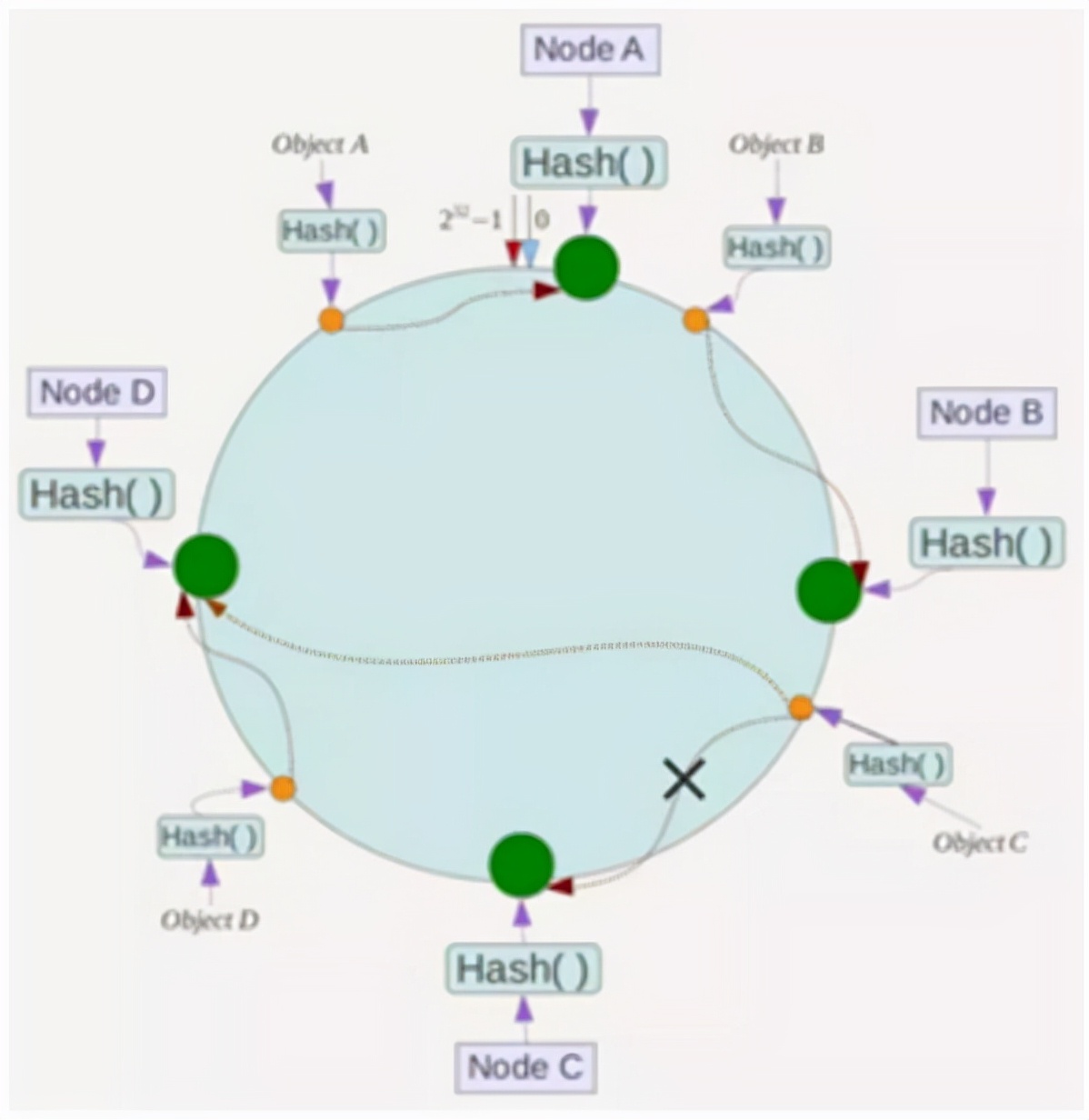
现在,假设节点c不幸崩溃,您可以看到目前不会影响对象A,B和D,并且只有对象C c c被重新安置到节点D。在一致的Hash算法中,如果服务器不可用,则受影响的数据仅在此服务器之间与第一个服务器之间的数据相同(如下所示,该数据仅在其环形空间中所示,该数据是在其环形空间中所处的,该数据是在该环形空间中所处的,该数据是在此环形空间中所处的。 NodeB,下面受影响的图是Objectc),其他人不会受到影响,如下所示:
考虑下面的另一种情况。如果将服务器节点X添加到系统中,如下图所示:
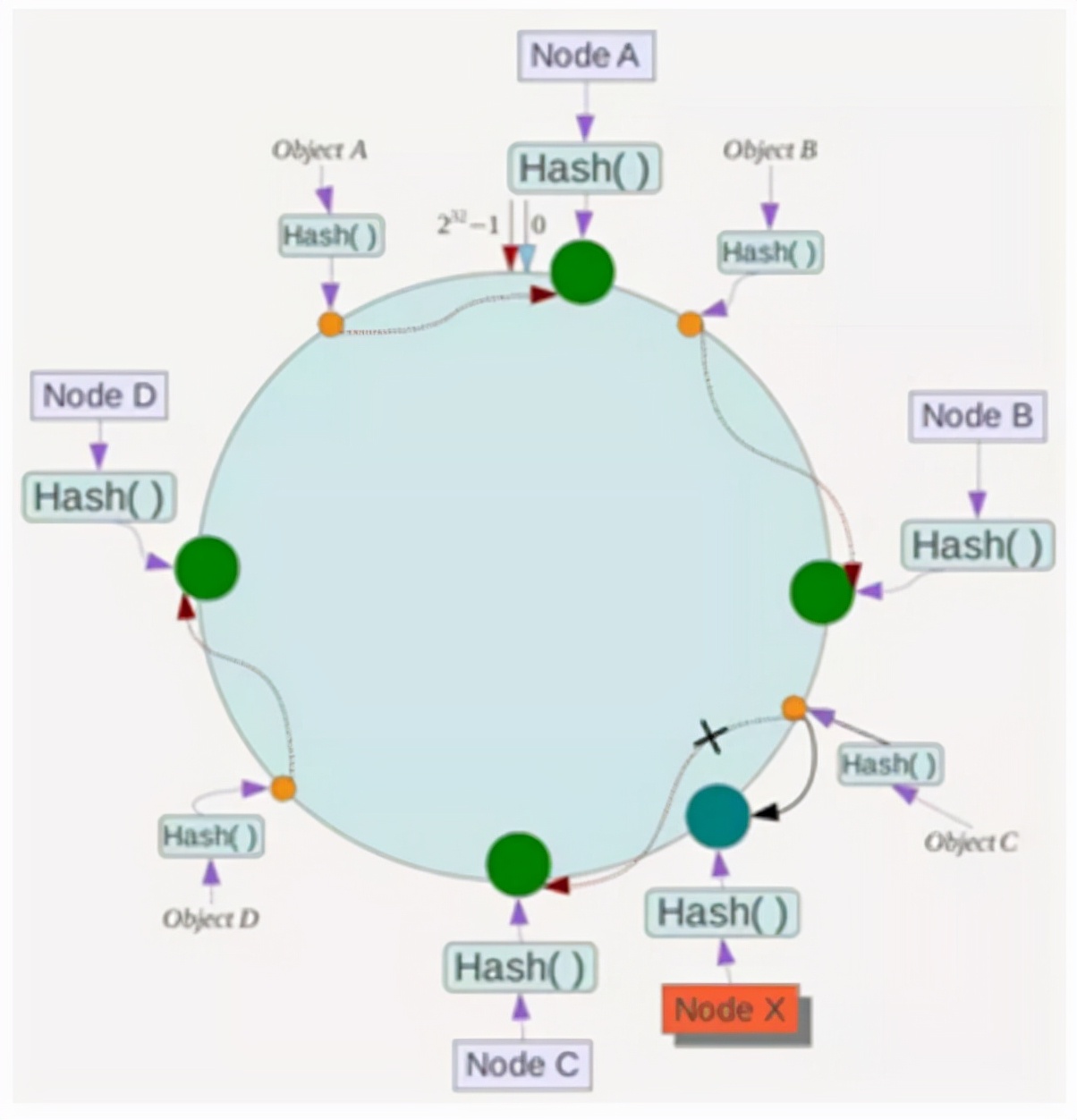
目前,对象对象A,B和D不受影响,仅需要将对象C重新安置到新的节点X!通常,在一致的哈希算法中,如果添加了一台服务器,则受影响的数据仅是新服务器和上一个服务器之间的数据(即,在逆时针行走时遇到的第一台服务器),其他数据将不会受到影响。
总而言之,一致的哈希算法只需要重新放置环空间中的一小部分数据即可增加节点的添加和减小,从而具有良好的容错性和可扩展性。
哈希环的数据偏斜问题
当服务节点太少时,由于节点分布不平kaiyun全站网页版登录,一致的哈希算法容易偏向数据(大多数缓存对象都在某个服务器中缓存)。例如,系统中只有两个服务器,环分布如下:
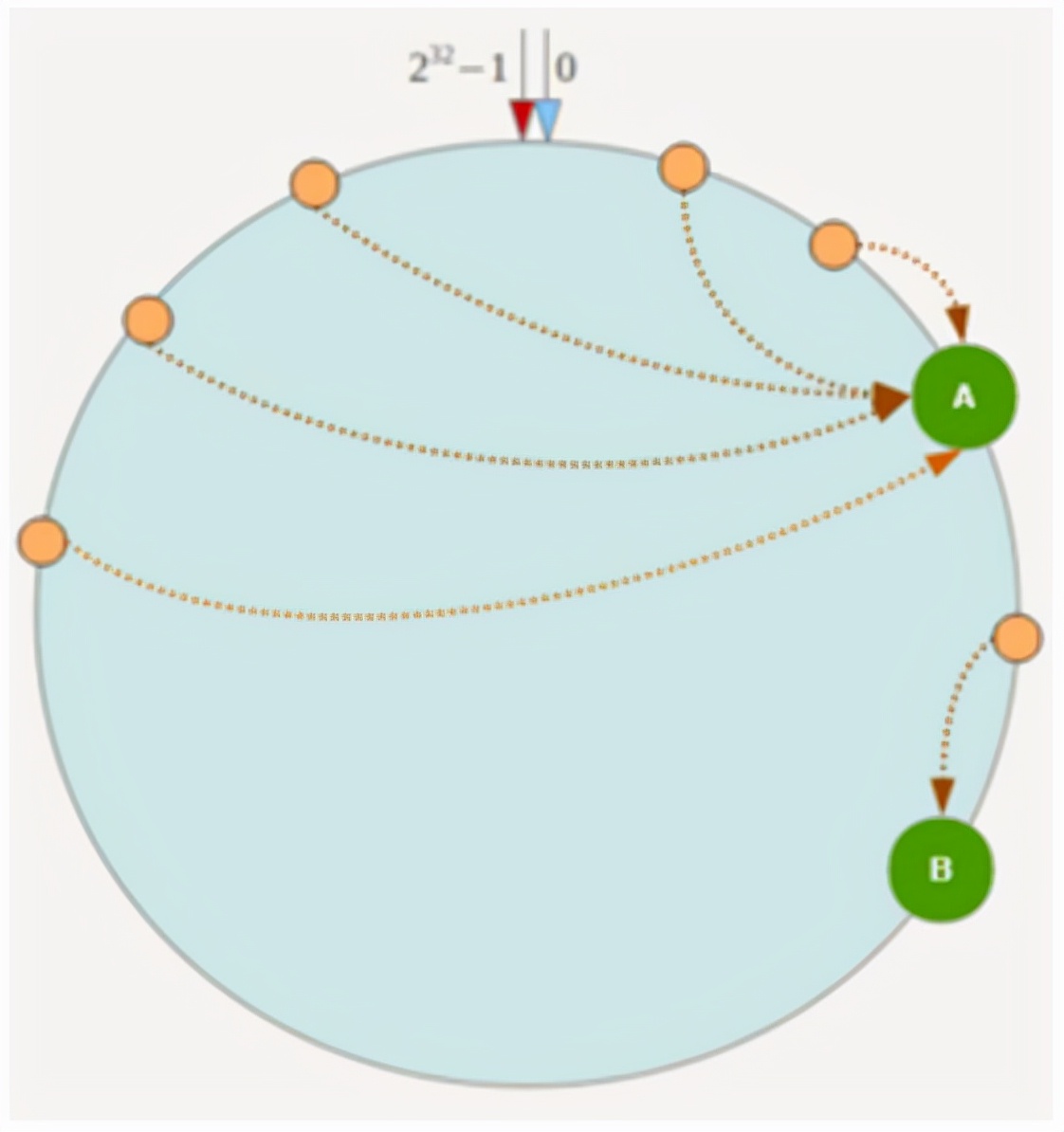
目前,大量数据将不可避免地集中在节点A上,并且在节点B上只有很少的数据将位于节点B上。为了解决此数据偏斜问题,一致的哈希算法引入了虚拟节点机制,即,对于每个服务节点,将多个服务节点计算出一个名为每个计算的位置,将多个hashe放置在每个服务节点上。可以通过在服务器IP或主机名之后添加数字来实现特定实践。
例如,在上述情况下,可以为每个服务器计算三个虚拟节点,因此“节点a#1”,“ node a#2”,“ node a#3”,“ node a#3”,“ node b#1”,“ node b#2”,“ node b#2”和“ node b#3”的哈希值分别可以分别计算出来,以便可以分别计算出六个虚拟节点。
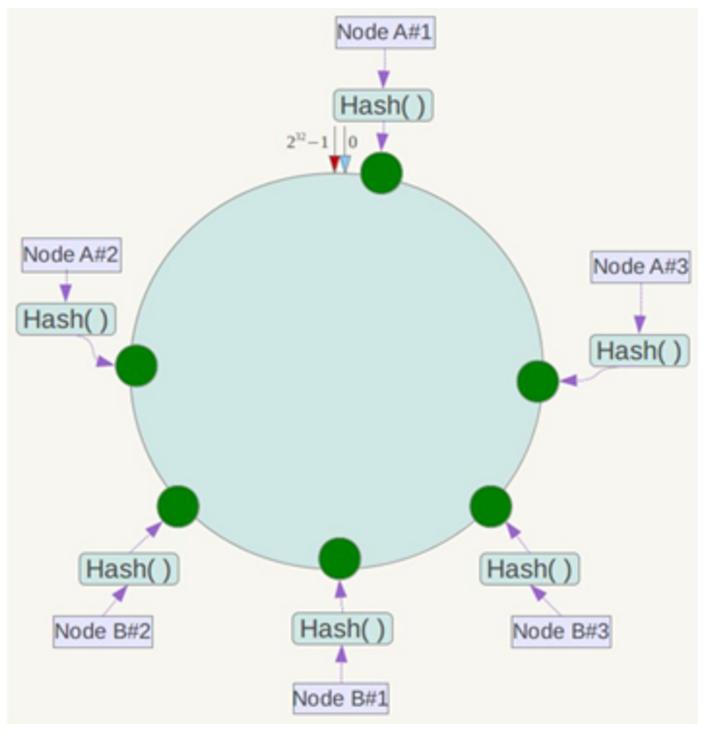
同时,数据定位算法保持不变,但是将虚拟节点映射到实际节点只有一个步骤。例如,位于三个虚拟节点“节点a#1”,“节点A#2”和“ Node A#3”的数据都位于节点A上。这解决了当很少的服务节点时,该问题解决了数据偏差的问题。在实际应用中,虚拟节点的数量通常设置为32甚至更大,因此即使有一些服务节点也可以实现相对均匀的数据分布。公共点的原理如下图所示:
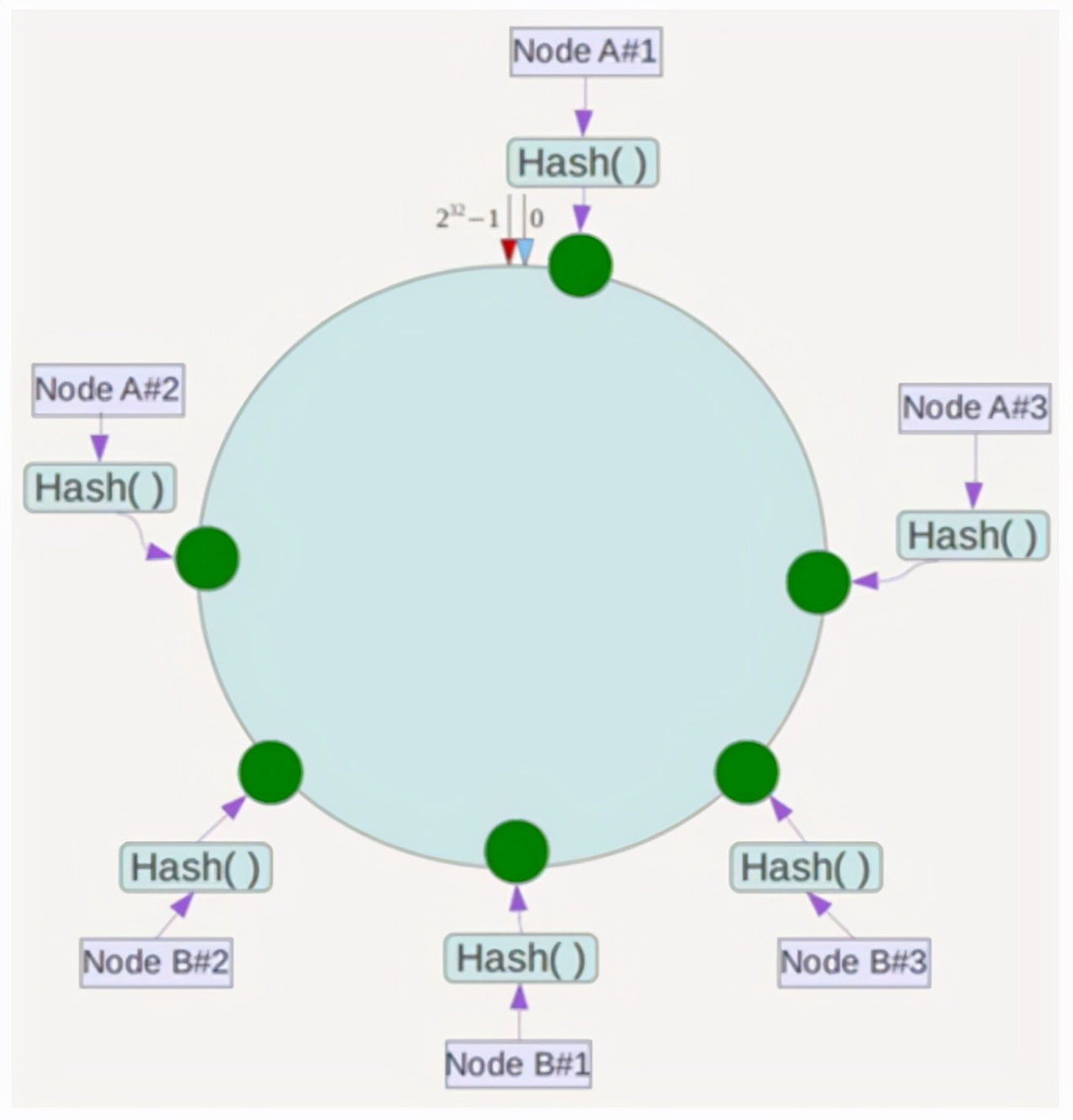
由于虚拟节点v1和v2映射到真实节点N1时,当数据对象1确定哈希环上的位置并找到虚拟节点v2时,其真实位置位于实际节点N1上。






