Interspech 2024将于9月1日至5日在希腊KOS举行。作为世界上最大的发音科学专业会议,该会议旨在展示最新的研究结果,探索语音应用的新机会,并促进语音技术的发展。该协会是语音领域的顶级会议之一。
本文收集并汇编了活动时间表,挑战,一些论文和会议技巧开yun体育app官网网页登录入口,供您参考。数据厅还将在Interspeech 2024展览的01号展位上亮相,以分享我们在语音领域的最新解决方案。请继续关注。

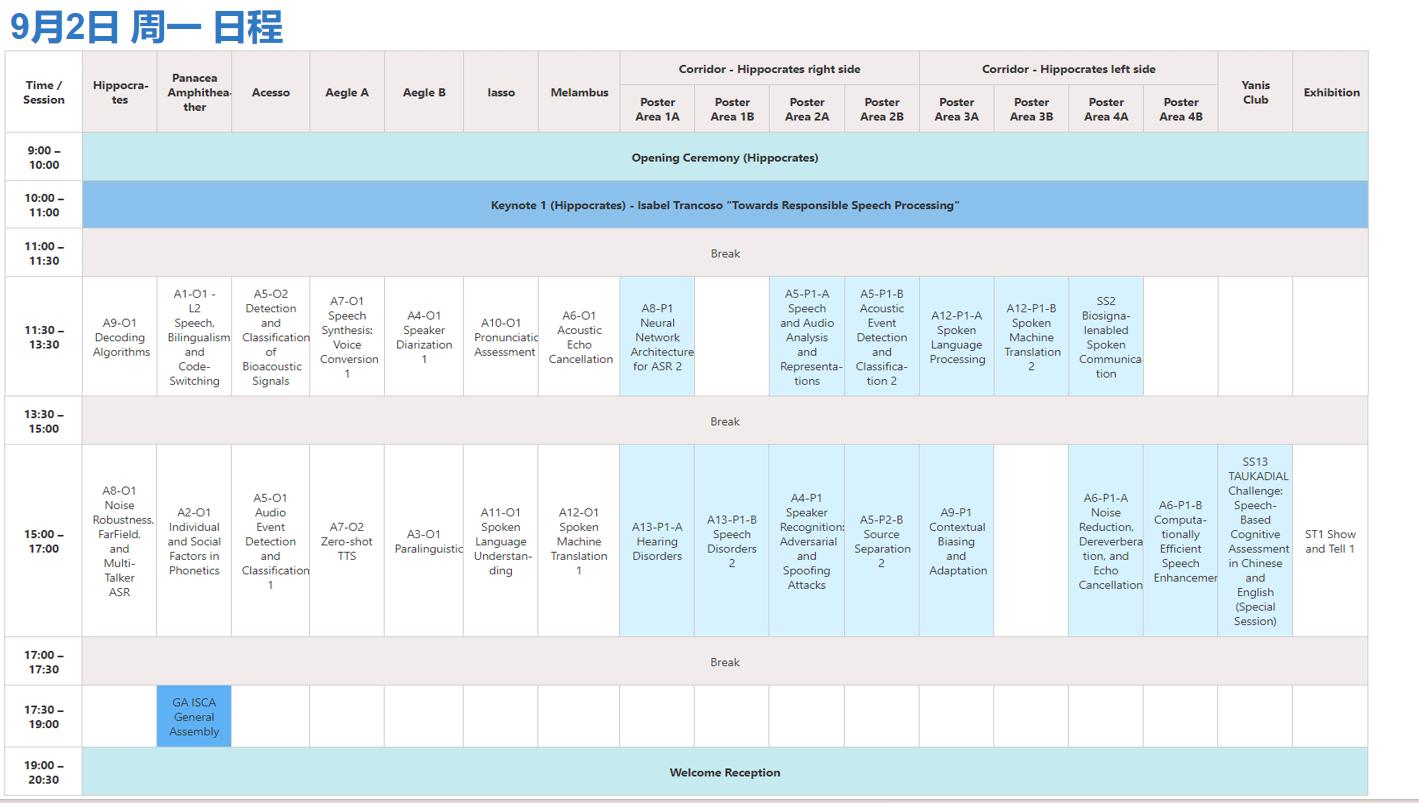
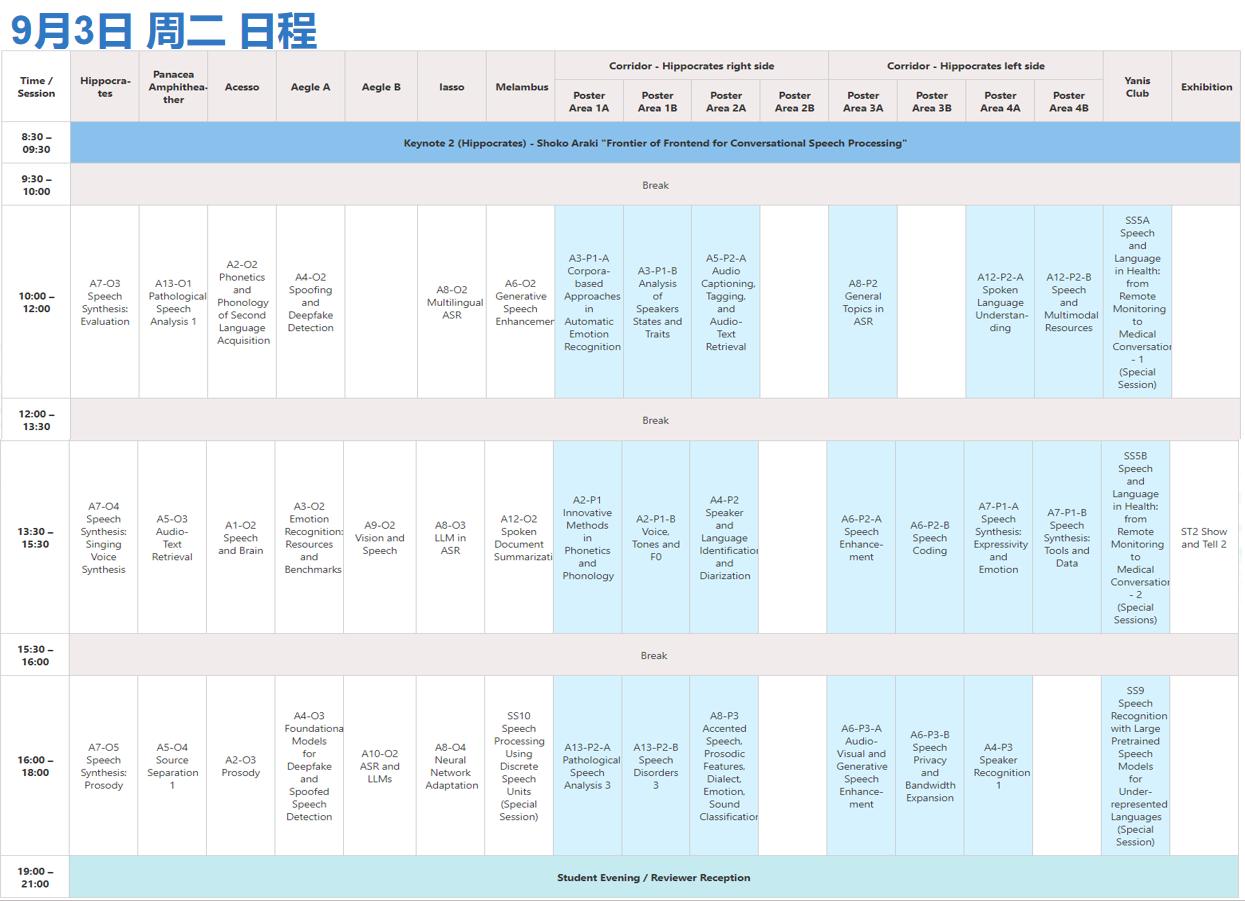
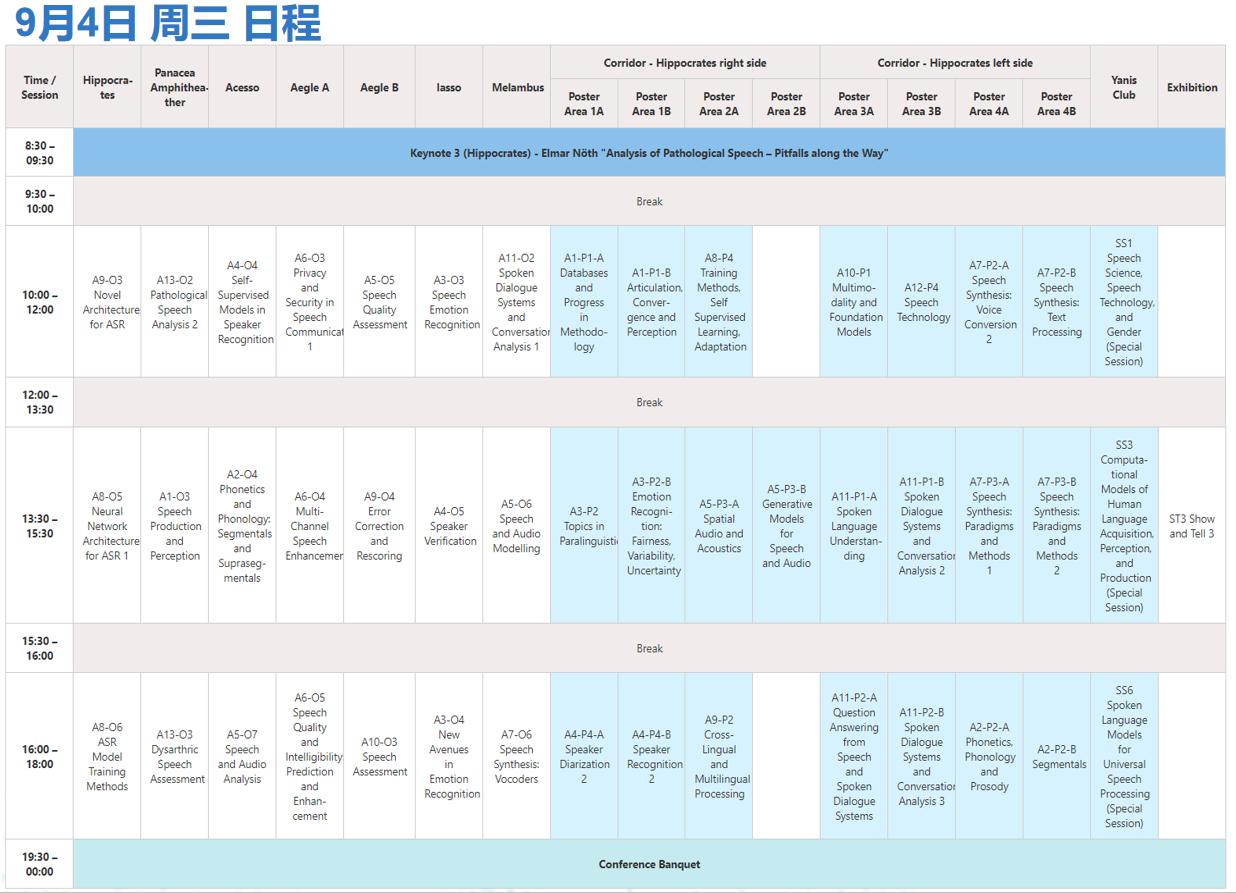
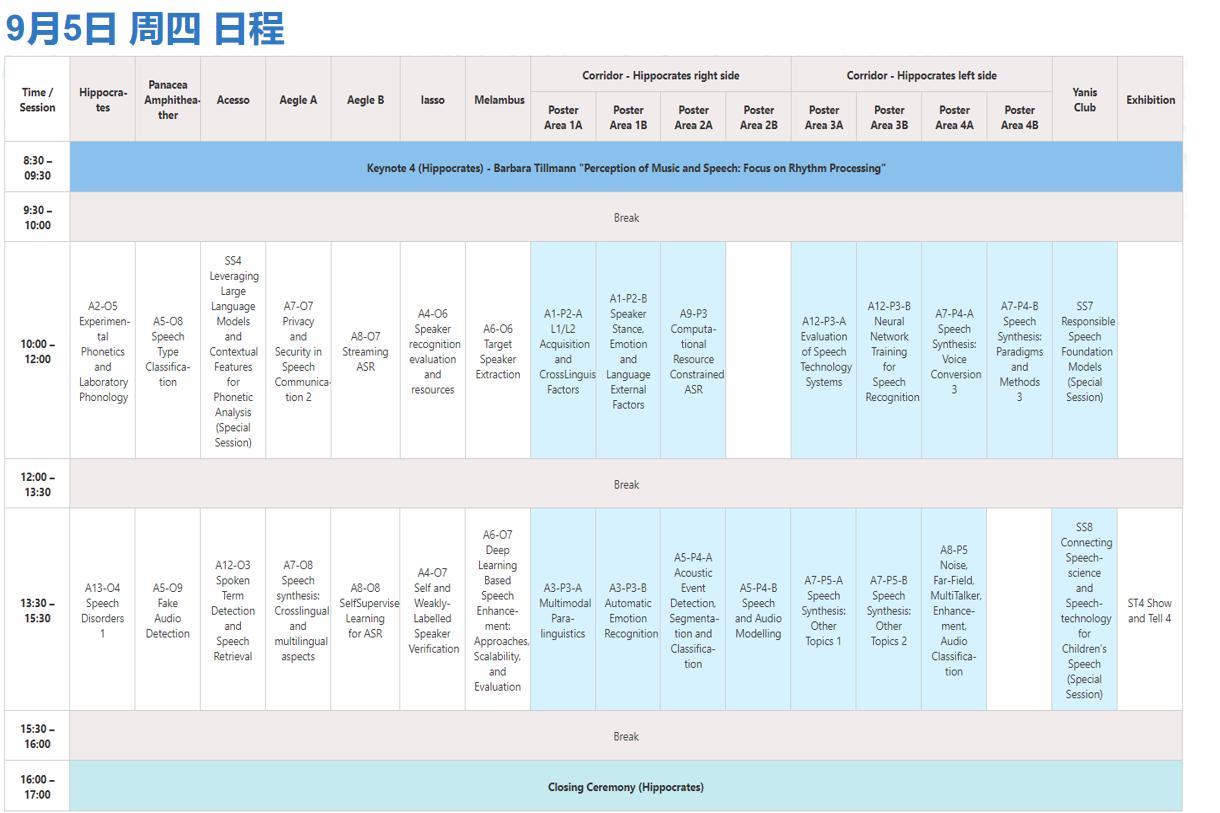
01会议时间表
(9月2日正式开放 - 会议于9月5日结束)
02挑战
使用离散语音单位挑战的语音处理
【引言】在传统的语音处理方法中,该模型通常采用从这些波形作为输入中提取的原始波形或高维特征。例如,光谱语音特征仍被广泛使用,而基于学习的深度神经网络特征近年来引起了极大的关注。一个有希望的替代方法是使用离散的语音表示,在该工作中,可以通过离散标记表示语音信号,如本工作所示。
【路】
1.ASR:评估所提出的数据所提出系统的ASR性能。
2.TTS:评估产生的语音的质量。
3。语音综合:评估合成人声的质量。
在对话环境中说话者和语言的第二次诊断(位移)挑战
【简介】位移2024挑战侧重于多语言扬声器部门的新限制和进度,在多演讲者环境中的语言部门以及混合代码/交换代码和多价方案中的自动语音识别,并评估了相同的数据集。
组织者发布了超过100个小时的数据(包括监督和无监督的数据)进行开发和评估。无监督的域匹配数据将发布给参与者以进行模型适应。竞争不提供培训数据,参与者可以自由使用任何资源来培训模型。
【路】
1。多语言场景中的语音划分。
2。在更多演讲者的环境中的语言划分。
3。在多重化环境中自动识别。
中文和英语(Taukadial)挑战的基于语音的认知评估
【引言】认知问题,例如记忆力丧失,语言和言语障碍和推理困难,经常发生在老年人群中,通常是阿尔茨海默氏病的前身。关于预防阿尔茨海默氏病和早期检测的认知障碍的研究已成为医疗保健领域的关键需求,采用具有成本效率且可扩展的认知评估和疾病检测方法。语音是一种易于收集的行为信号,反映了认知功能,因此有可能成为认知功能的数字生物标志物。
尽管迄今为止的大多数研究都集中在英语发音数据上,但《道卡挑战》旨在探索在全球健康背景下作为认知标记的发音潜力,为中文和英语提供数据。 《讽刺挑战》的任务将集中于对老年人的中文和英语认知测试评分的预测以及对轻度认知障碍的诊断(MCI)。
03论文
wenetspeech4tts:大型语音生成模型基准的12,800小时普通话TTS语料库
[论文的作者] Ma Linhan*,Guo Dake*,Song Kun,Jiang Yuepeng,Wang Shuai,Xue Liumeng,Xu Weiming,Zhao Huan,Zhang Binbin,Xie Lei(*对这项工作代表同样的贡献)
[论文单位]西北理工大学,深圳大数据研究所,香港汉大学(深圳),威内特开源社区,上海bigmelon Technology
【书突出显示】本文提出了一个多域普通话数据集,用于从开源Wenetspeech数据集改进的TTS任务,其中包含12,800小时的配对音频和文本数据。我们根据不同级别的质量评估得分将wenetspeech4tts分开,并训练和微调了VALL-E和NaturalSpeech 2系统,以验证数据集可用性,并为公平比较基准标准提供基线模型。数据集,相应的基准和模型权重都是开源的。
[论文介绍]随着大型文本到语音(TTS)模型的开发以及培训数据量表的扩展,最先进的TTS系统实现了令人印象深刻的性能。本文提出了wenetspeech4tts,这是一种源自开源wenetspeech数据集的多域普通话语料库。我们通过调整剪辑边界,提高音频质量并消除具有多个扬声器的剪辑来改善WenetsPeech,以适应TTS任务。在更准确的转录操作和基于数据质量的过滤过程之后,获得了包含12,800小时的配对音频和文本数据的wenetspeech4tts语料库。此外,我们根据不同级别的质量评估得分来划分不同大小的子集,以训练和微调TTS模型。我们在这些子集上培训并微调了VALL-E和NaturalSpeech 2系统,以验证WenetsPeech4TTS的可用性,同时为相当对比的TTS系统的基准构建基线模型。 wenetspeech4tts语料库,相应的基准和受过训练的模型的权重均在拥抱面上公开获得。
BS-PLCNET 2:具有模型内知识蒸馏的两阶段带状分组损耗隐藏网络
[论文的作者] Zhang Zihan,Xia Xianjun,Huang Chuanzeng,Lin Danfeng,Xie Lei
【论文单位】西北理工大学
[本文的简短亮点]本文提出了一个新的两级数据包丢失隐藏网络-BS-Plcnet 2,该网络是BS-PLCNET的升级版本。得益于模型中的知识蒸馏,BS-PLCNET 2在ICASSP 2024 PLC挑战盲验测试集中达到了最先进的PLCMOS性能,其计算复杂性仅为BS-PLCNET的38.1%,模型参数仅为40 BS-Plcnet。 %。此外,在单个训练过程中可以同时获得因果模型和非因果模型。
[纸简介]音频数据包丢失是实时语音交流中不可避免的问题。最近,我们提出了一个用于全带信号的频带分割的数据包丢失隐藏网络(BS-PLCNET)。尽管它在ICASSP 2024 PLC挑战中表现良好,但BS-PLCNET是一个大型模型,高计算复杂性为8.95g。为此,我们提出了改进的BS-PLCNET 2版本,以进一步降低计算复杂性并提高性能。具体而言,为了弥补未来缺失的信息,在宽带模块中,我们设计了双路径编码器结构(具有非因果关系和因果路径),并使用了模型内知识蒸馏策略来从非carusal中提取未来的信息教师到因果学生道路。此外,我们在数据包丢失恢复后引入了一个轻巧的后处理模块,以恢复语音失真并从音频信号中删除残留的噪声。 BS-PLCNET 2仅具有参数量的40%和BS-PLCNET计算体积的38%,并且在ICASSP 2024 PLC挑战盲套件上取得了0.18 PLCMOS的改善,可在此数据集上实现SOTA性能。
AS-70:一个普通话的口吃语音数据集,用于自动语音识别和口吃事件检测
【论文的作者】锣隆*,Xue Hongfei*,Wang Lezhi,Xu Xin,Li Qisheng,Li Qisheng,Xie Lei,Bu Huikaiyun.ccm,Wu Shaomei,Zhou Jiaming,Zhou Jiaming,Qin Yong,Qin Yong,Zhang Binbin,du Jun,du Jun,binjia,binjia,binjia,binjia,binjia,li ming,li ming,li ming,li ming
[论文单位]西北理工大学,斯塔默特尔克,希尔·壳云开·全站体育app登录,艾姆力,南凯大学,韦内特开源社区,中国科学技术大学,昆山杜克大学
[书籍亮点]发布了第一个公共普通话的语音数据集AS-70,它也是同一数据集中最大的公共语音数据集AS-70;已经建立了一种新的语音识别和口吃事件检测的基准。
[论文介绍]语音技术在过去二十年中取得了迅速的进步,并且在自动语音识别(ASR)的语音任务中取得了与人类接近的水平。但是,当这些模型应用于非典型发音(例如口吃)时,它们的效果会大大降低。本文介绍的AS-70是第一个公共普通话口吃数据集,它也是其相似数据集中最大的。 AS-70包括对话和语音命令,以读取发音,包括逐字手册笔录,适合研究各种与发音相关的任务的研究。此外,我们还建立了一个基准系统,并为ASR和口吃事件检测(SED)任务展示了实验结果。通过将该数据集纳入模型微调中,可以观察到,Whisper和Hubert等最先进的ASR模型已经显着改善,从而增强了它们在处理口吃的发音中的包含。
超越性能高原:一项有关语音增强性可伸缩性的综合研究
【论文的作者】Zhang Wangyou1,Kohei Saijo2,Jee-Weon Jung3,Li Chenda1,Shinji Watanabe3,Qian Yanmin1
【论文单位】1上海jiootong University Audiocc Lab,2 Waseda University,3 Carnegie Mellon University Wavlab
【书突出显示】本文在不同的模型复杂性,不同的培训数据量,因果/非可靠模式等下,深入探讨了不同体系结构(BSRNN,CORV-TASNET,DEMUC-V4,TF-GRIDNET)的语音增强模型。能力。相关实验使用了来自多个字段(VCTK+需求,DNS-2020,Whamr!,Chime-4,Reverb)的公共数据来评估模型的概括能力以及处理不同声学环境的普遍性。实验结果揭示了不同模型体系结构的扩大功能的显着差异,还指出了在语音增强领域需要探索的研究方向,例如构建大型多域数据集和设计模型可以有效缩放的体系结构。
[论文介绍]关于语音增强的大多数研究仅限于具有较小数据量(例如VCTK+需求)或单个域(例如DNS-2020)的数据集,并且绩效评估通常仅在相应分开的测试中进行套。这使得研究人员很难理解不同语音增强模型的实际概括和规模能力。为了填补这一研究差距,本文探讨了语音增强领域中的几种通用模型架构,并通过广泛的实验比较和分析有关模型复杂性和训练数据量的语音增强模型的规模能力。
该论文首先对BSRNN架构进行了系统的调查。实验结果表明,该模型架构的非伴侣模型的规模和概括能力明显优于因果模型,并且语音增强性能与模型复杂性相对一致。相关,但是模型性能在较少的培训数据(例如仅使用9小时VCTK+需求数据)时显示出“双重下降”现象,这表明很难准确地反映语音增强模型的真正功能。
另一方面,当通过合并不同域的数据扩大训练数据量时,BSRNN的语音增强性能还显示了随着培训数据量的增加而持续改善的趋势。但是,当通过模拟大量单场数据来进一步扩展语音数据量表时,语音增强性能实际上会下降,这表明在扩展数据量时,确保数据多样性对于语音增强的概括非常重要模型。
最后,本文比较了有关模型复杂性,训练时间和参数数量的不同模型体系结构的规模功能。结果如下图所示,其中BSRNN和TF-GRIDNET分别显示出较低和更高复杂性的最大比例能力。他们俩都采用了时频域双通道建模网络体系结构,这反映了IT提供了这种体系结构的强大表示。但是另一方面,这些模型架构是基于RNN设计的。随着模型的复杂性继续增加,其并行化能力的缺陷逐渐出现,从而导致训练效率非常低。因此,设计具有较高计算效率和强大功能的语音增强体系结构是一个紧迫的问题。
CODECFAKE:用于检测基于LLM的DeepFake音频的初始数据集
[论文的作者] lu yi*,Xie Yuankun*,Fu Ruibo,Wen Zhengqi,Tao Jianhua,Wang Zhiyong,Qi Xin,Liu Xuefei,Li Yongwei,Liu Yongwei,Liu Yukun,Wang Xiaopeng,Shi Shuchen(*代表相同的贡献,*这项工作)
【论文单位】中国科学院中国科学院自动化研究所
[纸本]本文提出了一个名为CodeCfake的数据集,该数据集是第一个检测大型语言模型(LLM)合成的深假音频的数据集。该数据集是由七个代表性神经编码器方法生成的假音频,涵盖了当前主流LLM音频生成模型。 CODECFAKE数据集总共包含1,058,216个音频样本,其中包括132,277个真实音频样本和925,939个假音频样本。该数据集的实验结果表明,使用CodeCfake数据集训练的音频DeepFake检测(ADD)模型的性能明显优于在基于编解码器检测DeepFake Audio的添加模型,从而有效地提高了检测准确性的性别和泛化能力。
关于论文】
随着大型语言模型(LLM)在音频生成中的发展,生成了越来越多的DeepFake音频。这些新的音频生成方法采用了端到端的神经编解码器技术,这与传统的依赖于Vocoder的生成方法不同。这给现有的音频深击检测(ADD)模型带来了挑战,因为它们主要依赖于Vocoder工件进行检测。
为了应对这一挑战,我们提出了CodeCfake数据集,该数据集是一个初始数据集,该数据集致力于检测基于LLM的DeepFake音频。该数据集包括七种涵盖当前主流音频生成技术的代表性神经编解码器方法。通过使用CodeCfake数据集,我们希望在检测基于编解码器生成的DeepFake音频时评估和提高添加模型的性能。实验结果表明,基于VOCODER训练的添加模型在检测基于编解码器生成的音频时很差,并且无法有效地区分真实音频和假音频。相比之下,添加在各种测试条件下使用CodeCfake数据集训练的模型,大大降低了平均误差率(EER),表明检测任务中的概括能力更好。简而言之,CodeCfake数据集为检测基于LLM的DeepFake音频提供了重要的工具,可帮助研究人员开发更有效的检测方法来改善音频伪造的保护。
04参加会议的技巧
场地信息

Kipriotis酒店与会议中心(KICC),
psalidi,85300 KOS,希腊
流量信息
公共汽车:展览建议乘公共汽车前往机场的科斯城,并转移到1号公共汽车(Agios Fokas方向)或5号公共汽车(Therma Direction)到Kipriotis村/KICC。
出租车:出租车停靠站位于机场抵达大厅前。请注意,岛上没有Uber服务。
此外,展览会还与当地合作伙伴共同提供公交车和下车服务。有关详细信息,请参阅Interspeech官方网站(单击“跳跃”)。
数据厅展览信息
数据厅期待在Interspeech 2024的现场与您会面。这次,我们将展示大型模型,多模式,ASR,TTS等领域中数据厅的最新数据解决方案,并分享我们的见解和经验语音圈子中的学者和公司代表。
展览时间:9月2日至9月5日
展位展位:KICC地点01号展位
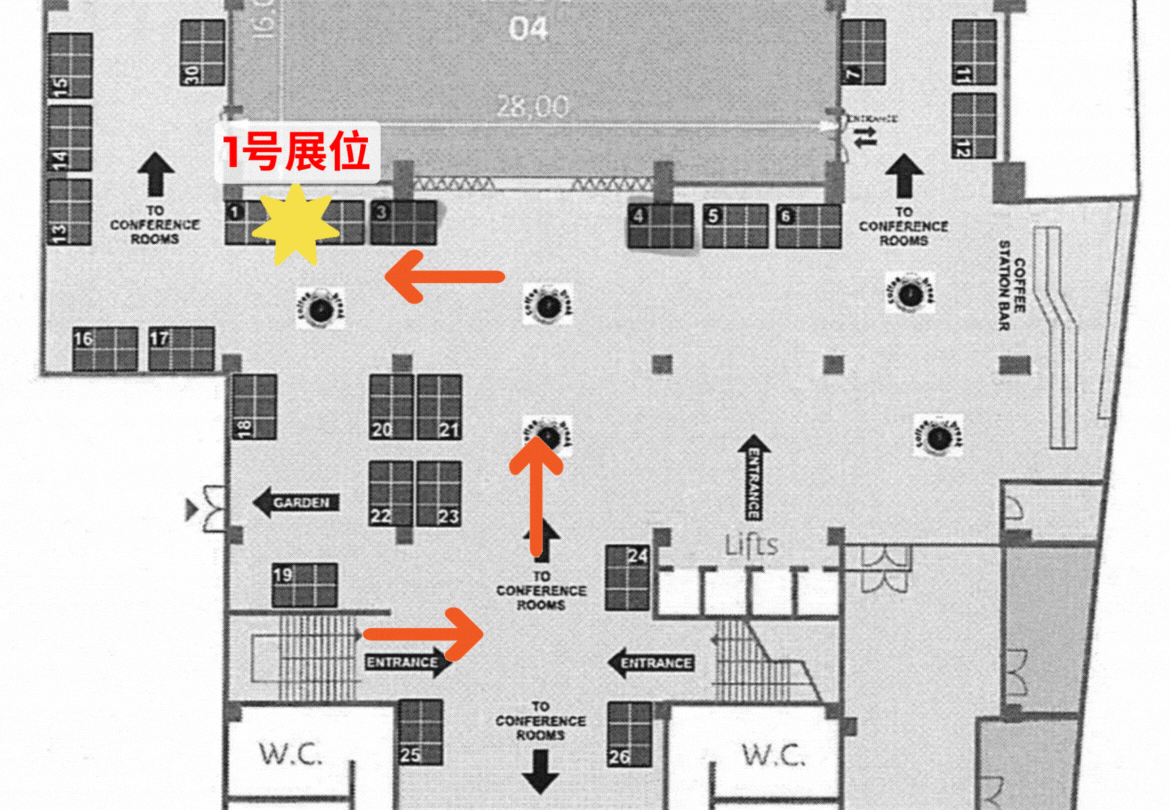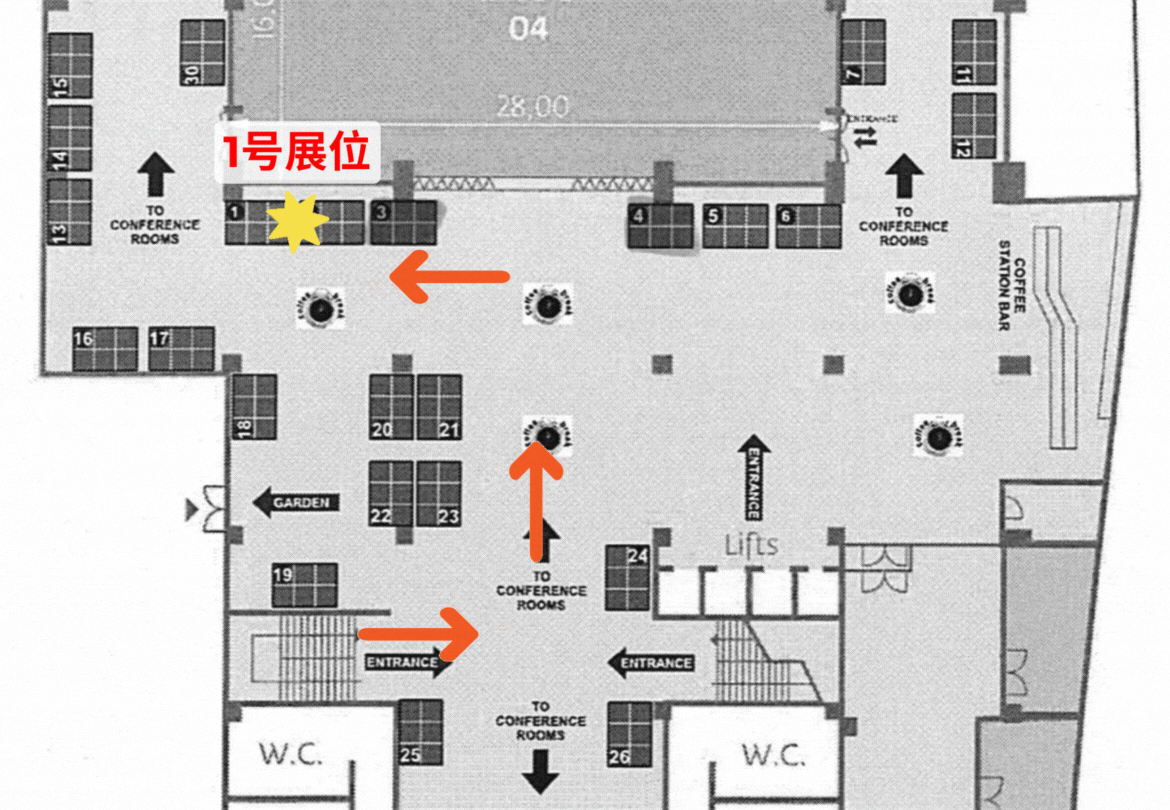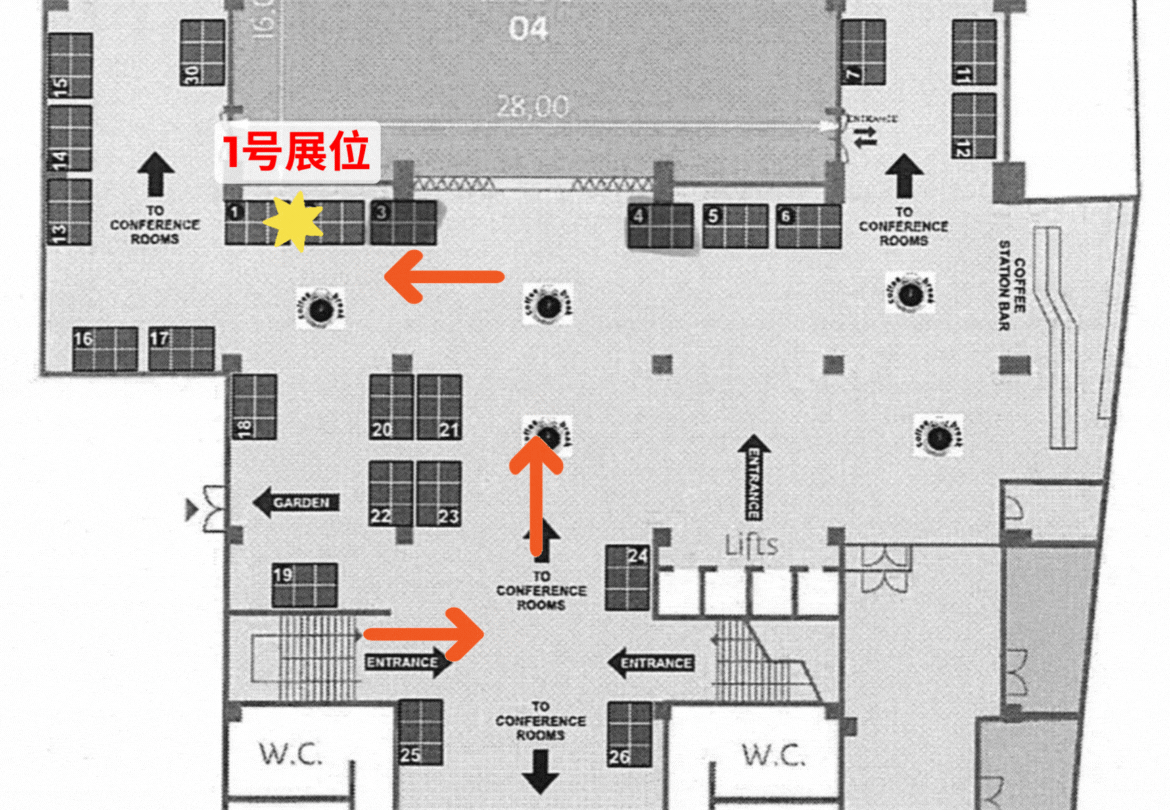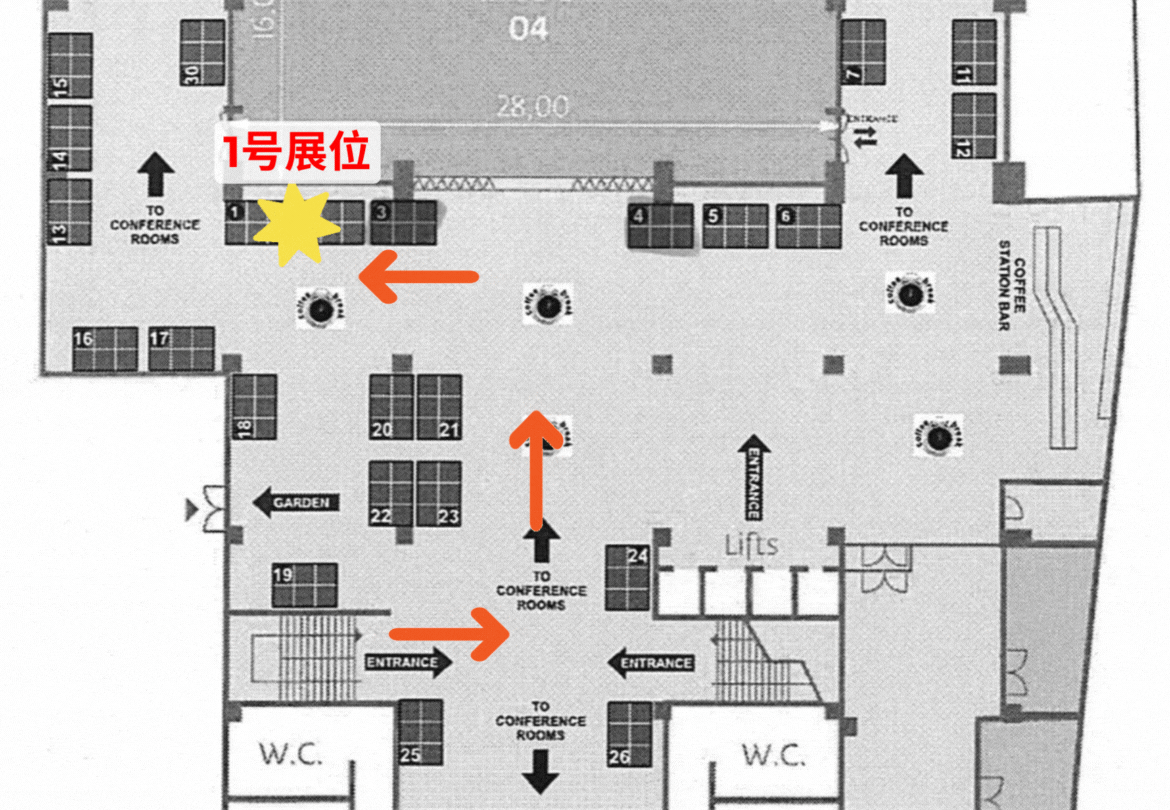
期待在Interspeech 2024与您会面!






